Python (한글사용, 파이그래프, 상자수염, Seaborn, 데이터전처리, 시본 막대그래프, 시본 산점도, 상자그림, 산점도, 막대, 연습문제)
1. 한글사용
- 폰트를 변경하지 않으면 기본 폰트는 'sans-serif'
- 폰트를 변경하려면 다음과 같이 수행
- matplotlib.rcParams['font.family'] = '폰트 이름'
- matplotlib.rcParams['axes.unicode_minus'] = False
- matplotlib.rcParams['axes.unicode_minus'] = False는 한글 폰트를 지정한 후에
- 그래프에서 마이너스(-) 폰트가 깨지는 문제를 해결해줌
import matplotlib.pyplot as plt
import numpy as np
import matplotlib
matplotlib.rcParams['font.family'] = 'Malgun Gothic' # '맑은 고딕'으로 지정
matplotlib.rcParams['axes.unicode_minus'] = False
x = np.arange(0,5,1)
y1 = x
y2 = x + 1
y3 = x + 2
y4 = x + 3
plt.plot(x, y1, '>-r', x, y2, 's-g', x, y3, 'd:b', x, y4, '-.Xc')
plt.legend(['데이터1', '데이터2', '데이터3', '데이터4'], loc='best')
plt.xlabel('X 축')
plt.ylabel('Y 축')
plt.title('그래프 제목')
plt.grid(True)
plt.show()
2. 파이그래프
- 파이 그래프는 원 안에 데이터의 각 항목이 차지하는 비율만큼 부채꼴의 크기를 갖는 영역으로 이루어진 그래프
- 각 부채꼴 부분이 파이 조각처럼 생겨서 파이 그래프라고 함
- 파이 그래프에서 부채꼴 부분의 크기는 각 항목의 크기에 비례
- 전체 데이터에서 각 항목이 차지한 비율을 비교할 때 많이 이용
# plt.pie(x [, labels=label_seq, autopct='비율 표시 형식(ex: %0.1f)', shadow=False(기본) 혹은 True
# , explode=explode_seq, counterClock=True(기본) 혹은 False, startangle=각도 (기본은 0)])
# x는 배열 확인 시퀀스 형태의 데이터.
# pie()는 x를 입력하면 x의 각 요소가 전체에서 차지하는 비율을 계산하고 그 비율에 맞게 부채꼴 크기를 결정해서 파이 그래프를 그림.
# labels : x 데이터 항목의 수와 같은 문자열 시퀀스(리스트, 튜플)을 지정해 파이 그래프의 각 부채꼴 부분에 문자열을 표시.
# autopct : 각 부채꼴 부분의 항목의 비율이 표시되는 숫자의 형식을 지정.
# 예를 들어 '%0.1f'가 입력되면 소수점 첫째 자리까지 표시되며, '%0.0f'가 입력되면 정수만 표시.
# %를 추가하고 싶으면 '%0.1f%%'와 같이 입력.
# shadow : 그림자 효과를 지정. 기본 값은 False.
# explode : 부채꼴 부분이 원에서 돌출되는 효과를 주어 특정 부채꼴 부분을 강조할 때 이용.
# x 데이터 항목의 수와 같은 문자열 시퀀스(리스트, 튜플)을 지정. 기본 값은 강조 효과가 없음.
# counterClock : x 데이터에서 부채꼴 부분이 그려지는 순서가 반시계방향(True)인지 시계방향(False)인지를 지정.
# 기본값은 True로 반시계 방향.
# startangle : 제일 처음 부채꼴 부분이 그려지는 각도로 x축을 중심으로 반시계 방향으로 증가. 기본값은 0.
# 파이 그래프는 가로, 세로 비율이 1 대 1로 같아야 그래프가 제대로 보임.
# plt.figure(figsize = (w, h)
# w와 h는 그래프의 너비 width와 높이 height 를 의미. 단위는 인치 inch.
# 값을 지정하지 않으면 (w, h)의 기본값은 (6, 4).
# w와 h를 같은 값으로 지정하면 생성되는 그래프는 가로와 세로의 비율은 1 대 1이 됨.
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family'] = 'Malgun Gothic' # '맑은 고딕'으로 지정
matplotlib.rcParams['axes.unicode_minus'] = False
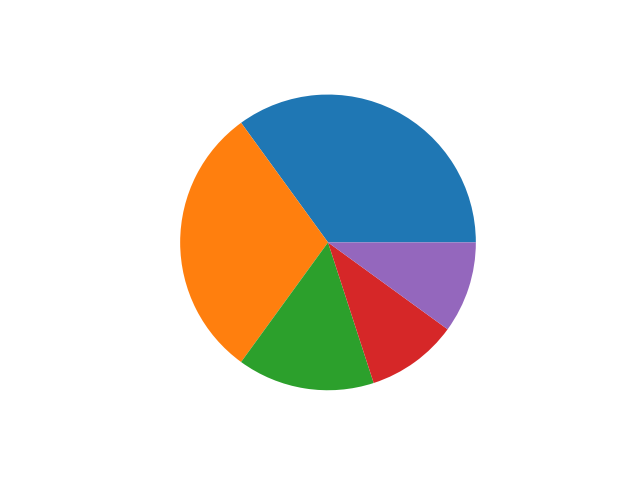
fruit = ['사과', '바나나', '딸기', '오렌지', '포도']
result = [7, 6, 3, 2, 2]
plt.pie(result)
plt.show()
# 각 부채꼴 부분에 속하느 데이터의 라벨과 비율을 추가
plt.figure(figsize=(7,7))
plt.pie(result, labels=fruit, autopct='%.1f%%')
plt.show()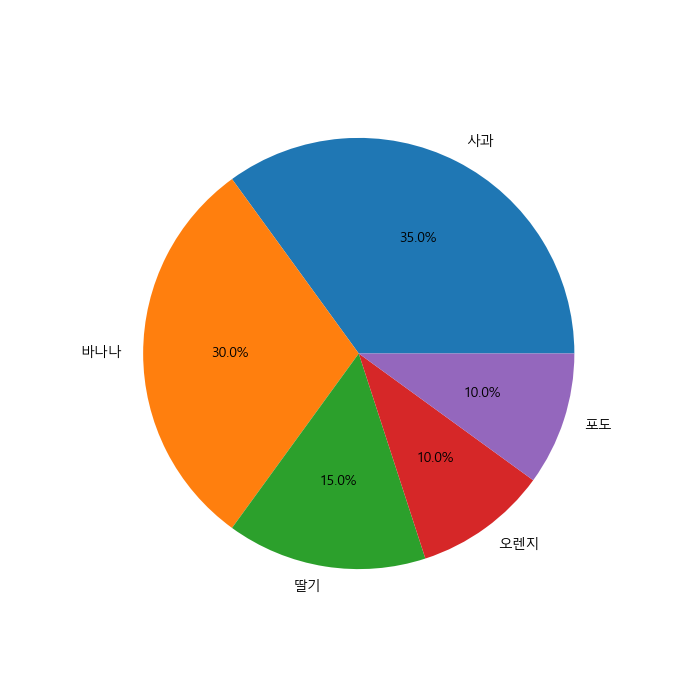
# 각 부채꼴 부분은 x축 기준 각도 0도를 시작으로 반시계방향으로 그려짐
# x축 기준 각도 90도에서 시작해서 시계방향으로 그려는 예
plt.figure(figsize=(7,7))
plt.pie(result, labels=fruit, autopct='%.1f&&', startangle= 90, counterclock=False)
plt.show()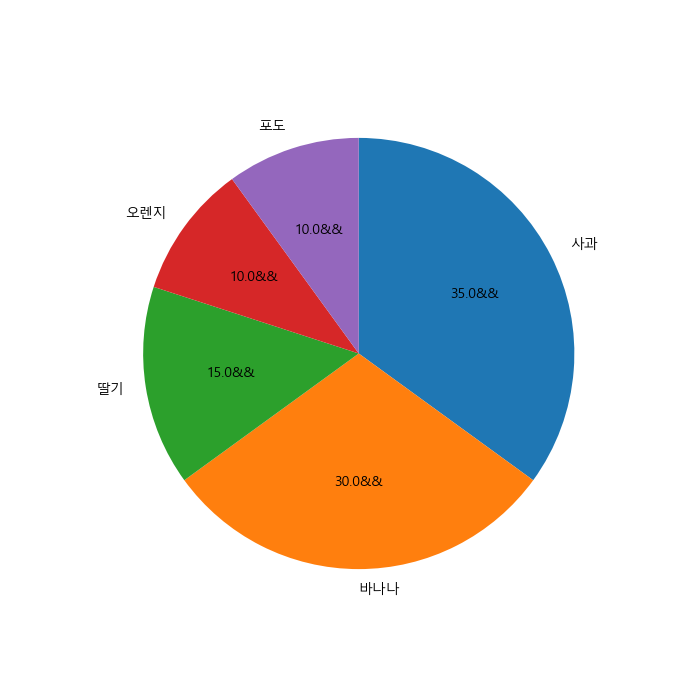
# 그림자를 추가하고, 특정 요소(사과)를 표시한 부채꼴 부분만 강조한 예
explode_value =(0.1, 0, 0, 0, 0)
# 0.1 : 반지름의 10% 만큼 벗어나도록 설정
plt.figure(figsize=(7,7))
plt.pie(result, labels=fruit, autopct='%.1f%%', startangle=90, explode=explode_value, shadow=True, counterclock=False)
plt.show()
3. 상자 수염 Box Plot 그래프
- '데이터 분포를 시각화'하여 탐색하는 방법으로 상자수염 그래프가 있음
- 사람의 나이가 500살, 키가 5미터 등은 표현은 가능하지만 현실적으로 불가능한 값들
- 이를 이상치, 극단치라고 하는데, 이상치는 효과적인 데이터 분석을 위해 제거해야 함
- 이상치를 제거하기 위해 값의 정상 범위를 정하는 방법이 있음
- 나이의 경우 0살에서 120살 까지를 정상 범위로 정한다면 121살은 이상치로 보는 것
- 또 다른 방법으로 통계적인 기법을 사용하는 것인데,
- 정규 분포에서 상하위 0.2% 밖의 데이터를 극단적인 값으로 가정하여 제거하는 것
4. 시본 Seaborn
- 시본 Seaborn 라이브러리는 맷플로립을 기반으로 다양한 테마와 통계용 차트 등의 동적인 기능을 추가한 라이브러리
- 시본 라이브러리는 맷플로립과 다르게 통계와 관련된 차트를 제공하기 때문에
- 데이터프레임으로 다양한 통계 지표를 만들어 낼 수 있으며 데이터 분석에 활발하게 사용되고 있음
- 시본 라이브러리로 그리는 그래프들은 크게 관계형, 분포형, 카테고리형의 세가지 범주로 분류할 수 있는데,
- 실제 분석에는 맷플로립과 시본 라이브러리 두 가지를 함께 사용
- 시본 라이브러리를 사용할 때 시본이 맷플로립에 의존적이기 때문에 맷프로립 라이브러리도 함께 임포트 해야함
- 시본 라이브러리의 주요 특징
- 1) 뛰어난 시각화 효과 2) 간결한 구문 제공 3) 판다스 데이터프레임에 최적화 4) 쉬운 데이터프레임 집계 및 차트 요약
- 시본 라이브러리는 기본적으로 맷플로립보다 제공하는 색상이 더 많기에 색 표현력이 좋음
- 맷플로립으로 그래프를 표현하더라도 시본의 set() 함수를 미리 선언해 주면 자동으로 시본 팔레트에 출력
- 시본은 'deep, muted, pastel, bright, dark, colorblind'의 6개 기본 팔레트를 제공
seaborn: statistical data visualization — seaborn 0.13.2 documentation
seaborn: statistical data visualization
seaborn.pydata.org
5. 데이터 전처리
# 2020년 건강검진 일부 데이터 엑셀 파일을 읽어와 동적인 시각화를 표현
# 1. 파일 불러오기
import pandas as pd
data = pd.read_excel('./input/health_screenings_2020_1000ea.xlsx')
print(data.head())
print(data.info())
# 2. 데이터 전처리
# 성별, 음주 여부, 흡연 상태에 대하여 숫자로 저장되어 있는 정보를 데이터 분석의 가독성을 높이기 위해
# 필요한 데이터만 추출
data6 = data[['gender', 'height', 'weight', 'waist', 'drinking', 'smoking']]
print(data6.head())
# 성별 데이터를 Male과 Female로 변경
data6.loc[data6['gender'] ==1, ['gender']] = 'Male'
data6.loc[data6['gender'] ==2, ['gender']] = 'Female'
# 음주 여부 0(비음주)는 Non-drinking, 1(음주)는 Drinking으로 변경
data6.loc[data6['drinking'] == 0, ['drinking']] = 'Non-drinking'
data6.loc[data6['drinking'] == 1, ['drinking']] = 'Drinking'
# 흡연상태 1(비흡연)과 2(흡연 끊음)을 Non-smoking으로 변경하고, 3(흡연)을 Smoking으로 변경
data6.loc[(data6['smoking'] == 1) | (data6['smoking'] == 2), ['smoking']] = 'Non-smoking'
data6.loc[data6['smoking'] == 3, ['smoking']] = 'Smoking'
print(data6.head())
print(data6.info())
# gender height weight waist drinking smoking
# 0 Male 165 60 72.1 Non-drinking Non-smoking
# 1 Female 150 65 81.0 Non-drinking Non-smoking
# 2 Female 155 55 70.0 Non-drinking Non-smoking
# 3 Male 160 70 90.8 Non-drinking Non-smoking
# 4 Female 155 50 75.2 Non-drinking Non-smoking
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 1000 entries, 0 to 999
# Data columns (total 6 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 gender 1000 non-null object
# 1 height 1000 non-null int64
# 2 weight 1000 non-null int64
# 3 waist 1000 non-null float64
# 4 drinking 1000 non-null object
# 5 smoking 1000 non-null object
# dtypes: float64(1), int64(2), object(3)
# memory usage: 47.0+ KB
# None
# 데이터 저장
data6.to_pickle('./output/data6.pickle')
6. 시본 막대 그래프
- 시본에서 사용하는 막대 그래프는 barplot() 함수로 속성 3개를 지정하여 범주별 그룹을 쉽게 표현할 수 있음
- 시본 막대 그래프는 기본적으로 오차 막대가 표시 되는데,
- 오차 막대를 그리는 범위를 신뢰구간이라고 함
- 오차 막대 신뢰구간을 표준편차로 하고 싶다면 ci 속성을 'sd'(ci='sd')로 지정
- 데이터 분석을 대부분 평균을 구하지만, 데이터에 극단치가 많을 때 중앙값을 확인하거나
- 범주형 데이터인 경우 그룹별 개수를 계산할 수 있음
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
data6 = pd.read_pickle('./output/data6.pickle')
print(data6.head())
# gender height weight waist drinking smoking
# 0 Male 165 60 72.1 Non-drinking Non-smoking
# 1 Female 150 65 81.0 Non-drinking Non-smoking
# 2 Female 155 55 70.0 Non-drinking Non-smoking
# 3 Male 160 70 90.8 Non-drinking Non-smoking
# 4 Female 155 50 75.2 Non-drinking Non-smoking
# 1. 데이터 준비하기
# 음주 여부 및 흡연 상태 데이터 준비하기
# data6에서 성별, 음주 여부의 그룹별 개수(인원)를 구하여 drinking에 저장
drinking = data6.groupby(['gender', 'drinking'])['drinking'].count()
print(drinking)
# gender drinking
# Female Drinking 213
# Non-drinking 305
# Male Drinking 356
# Non-drinking 126
# Name: drinking, dtype: int64
# data6에서 성별, 흡연 상태의 그룹별 개수(인원)를 구하여 smoking에 저장
smoking = data6.groupby(['gender', 'smoking'])['smoking'].count()
print(smoking)
# gender smoking
# Female Non-smoking 500
# Smoking 18
# Male Non-smoking 321
# Smoking 161
# Name: smoking, dtype: int64
# 음주 여부와 흡연 상태에 대한 그룹별 개수(인원)의 시리즈를 데이터프레임으로 변경
drinking = drinking.to_frame(name='count')
smoking = smoking.to_frame(name='count')
print(drinking)
# gender drinking
# Female Drinking 213
# Non-drinking 305
# Male Drinking 356
# Non-drinking 126
# 데이터프레임의 인덱스를 초기화
drinking = drinking.reset_index()
smoking = smoking.reset_index()
print(drinking)
# gender drinking count
# 0 Female Drinking 213
# 1 Female Non-drinking 305
# 2 Male Drinking 356
# 3 Male Non-drinking 126
- 2) 기본 막대 그래프 그리기
- add_subplot() 함수
- add_subplot() 함수의 인자를 통해 서브플롯 개수를 조정
- add_subplot(1,2,1)은 1 x 2 (행 x 열)의 서브플롯을 생성한다는 의미이고,
- 세 번째 인자 1인 생성된 두 개의 서브플롯 중 첫 번째 서브플롯을 의미
- 마찬가지로 (1, 2, 2)는 1 x 2 서브플롯에서 두 번째 서브플롯을 의미
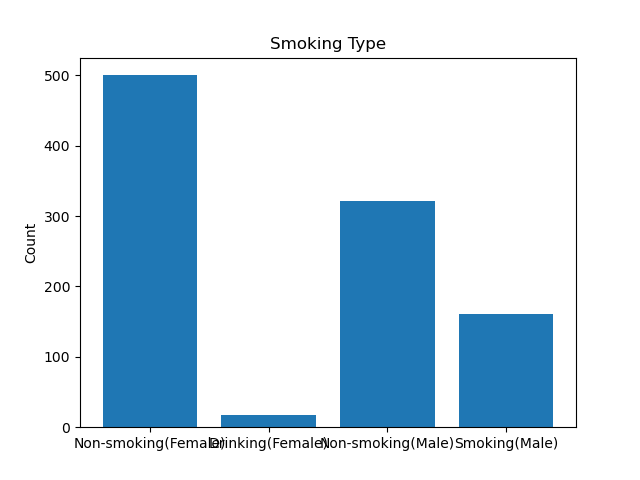
# 2. 기본 막대 그래프 그리기
# 성별 음주 여부 및 흡연 상태 막대 그래프
fig = plt.figure(figsize=(17, 6)) # 그래프 크기 지정 및 그림 객체 생성
fig.suptitle('2022 Health Screenings Drinking & Smoking Type Bar Graph', fontweight='bold')
index = np.arange(4) # x축 눈금 개수를 배열로 생성하고 index에 저장
# 2) 첫 번째 서브플롯 설정
fig.add_subplot(1, 2, 1) # 1행 2열의 서브플롯 중 첫 번째 서브플롯을 생성
# 첫 번째 서브플롯에 그려질 음주 여부 데이터 개수 (인원)을 bar() 함수를 이용하여 지정
plt.bar(index, drinking['count'])
plt.title('Drinking Type')
plt.ylabel('Count')
# x축 눈금 이름을 지정
plt.xticks(index, ['Non-drinking(Female)', 'Drinking(Female)', 'Non-drinking(Male)', 'Drinking(Male)'])
plt.show()
# 3) 두 번째 서브플롯 설정
fig.add_subplot(1, 2, 2) # 1행 2열의 서브플롯 중 두 번째 서브플롯을 생성
# 두 번째 서브플롯에 그려질 흡연 상태 데이터 개수 (인원)을 bar() 함수를 이용하여 지정
plt.bar(index, smoking['count'])
plt.title('Smoking Type')
plt.ylabel('Count')
# x축 눈금 이름을 지정
plt.xticks(index, ['Non-smoking(Female)', 'Drinking(Female)','Non-smoking(Male)','Smoking(Male)'])
plt.show()
# 3) 시본 막대 그래프 그리기
# 성별 음주 여부 및 흡연 상태 시본 막대 그래프
fig = plt.figure(figsize=(17, 6))
# 1행 2열의 서브플롯 생성
area1 = fig.add_subplot(1,2,1)
area2 = fig.add_subplot(1,2,2)
# barplot() 함수를 이용하여 x축에 성별, y축에 음주여부 개수 (인원), hue에 성별 음주 여부를 할당하여 첫 번째 서브플롯에 할당
ax1 = sns.barplot(data=drinking, x='gender', y='count', hue='drinking', ax=area1)
# barplot() 함수를 이용하여 x축에 성별, y축에 흡연상태 개수 (인원), hue에 성별 흡연상태 그룹별 데이터를 할당하여
# 두 번째 서브플롯에 할당
ax2 = sns.barplot(data=smoking, x='gender', y='count', hue='smoking', ax=area2)
fig.suptitle('2022 Health Screenings Drinking & Smoking Type Seaborn Bar Graph', fontweight='bold')
area1.set_title('Drinking Type')
area2.set_title('Smoking Type')
plt.show()
7. 시본 산점도 그래프
- 시본 산점도 그래프는 Strip Plot 그래프, Swarm Plot 그래프 등이 있음
- 맷플롯립의 산점도 그래프처럼 모든 데이터를 점으로 표현하는데,
- 맷플롯립의 산점도보다 범주에 따는 각 분포의 실제 데이터나 전체 형상등을 보여 준다는 장점이 있음
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
data6 = pd.read_pickle('./output/data6.pickle')
print(data6.head())
# 1. 데이터 준비하기
# data6에서 남성 및 여성의 성별, 몸무게, 허리둘레, 음주 여부, 흡연 상태 데이터를 가져와
# male_data, female_data에 각각 저장
male_data = data6.loc[data6.gender == 'Male', ['gender','weight', 'waist', 'drinking', 'smoking']]
female_data = data6.loc[data6.gender == 'Female', ['gender', 'weight', 'waist', 'drinking', 'smoking']]
print(male_data.head())
# gender weight waist drinking smoking
# 0 Male 60 72.1 Non-drinking Non-smoking
# 3 Male 70 90.8 Non-drinking Non-smoking
# 5 Male 85 94.0 Drinking Smoking
# 6 Male 80 93.0 Drinking Smoking
# 7 Male 65 92.0 Non-drinking Smoking
print(min(female_data['waist']))
# 53.0
print(max(male_data['waist']))
# 128.0
- 2) 시본 스트립 플롯 그래프 그리기
- stripplot() : 데이터 개수가 1개이고 변수의 종류가 연속적이거나 범주형인 데이터에 대해 간단히 요약한 그래프
- 상자수염 또는 바이올린 그래프를 보충하는 그래프로 많이 사용
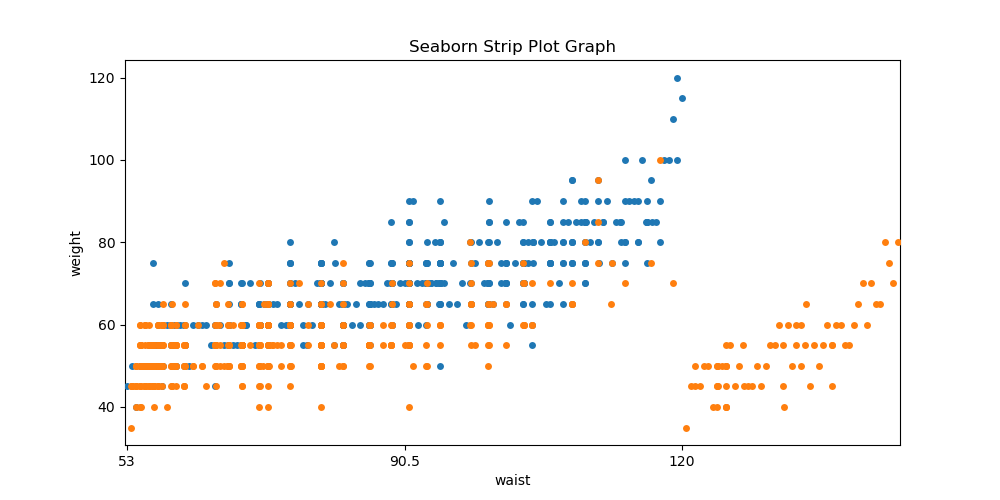
# 2. 시본 스트림 플롯 그래프 그리기
# 스트립 플롯 그래프는 데이터 분포를 요약하여 간략히 띠 형태로 보여 주는 그래프
# 일반적으로 작은 데이터를 다루는 용도로 사용되는데, 큰 데이터를 다룰 때는 주로 히스토그램 등을 많이 사용
plt.figure(figsize=(10, 5)) # 그래프의 크기를 지정
plt.title('Seaborn Strip Plot Graph') # 그래프의 제목을 지정
# stripplot() 함수로 허리 둘레 데이터를 x축에 지정, 몸무게 데이터를 y축에 각각 지정
sns.stripplot(data=male_data, x='waist', y='weight')
sns.stripplot(data=female_data, x='waist', y='weight')
# x축 눈금 간격(눈금 개수는 총 127개)을 허리둘레의 최솟값(53)과 최댓값(128)을 중심으로 지정
plt.xticks(np.arange(0, 127, 63), labels=[53, 90.5, 120])
plt.show()
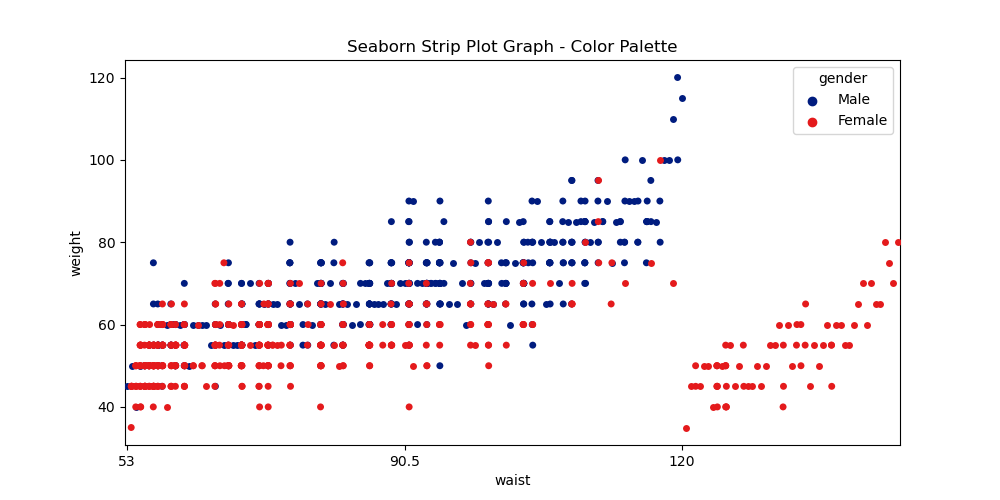
plt.figure(figsize=(10, 5)) # 그래프의 크기를 지정
plt.title('Seaborn Strip Plot Graph - Color Palette') # 그래프의 제목을 지정
# stripplot() 함수로 허리 둘레 데이터를 x축에 지정, 몸무게 데이터를 y축에 각각 지정
sns.stripplot(data=male_data, x='waist', y='weight', hue='gender', palette='dark')
sns.stripplot(data=female_data, x='waist', y='weight', hue='gender', palette='Set1')
# x축 눈금 간격(눈금 개수는 총 127개)을 허리둘레의 최솟값(53)과 최댓값(128)을 중심으로 지정
plt.xticks(np.arange(0, 127, 63), labels=[53, 90.5, 120])
plt.show()
8. 상자 그림 - 집단 간 분포 차이 표현하기
- 상자 그림 box plot은 데이터의 분포 또는 퍼져 있는 형태를 직사각형 상자 모양으로 표현한 그래프
- 상자 그림을 보면 데이터가 어떻게 분포하고 있는지 알 수 있기 때문에 평균값만 볼 때 보다
- 데이터의 특징을 더 자세히 이해할 수 있음
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# 01. 상자 그림만들기
# sns.boxplot()을 이용하면 상자 그림을 만들 수 있음
# mpg 데이터를 이용해 x축을 drv, y축을 hwy로 지정하고 '구동 방식별 고속도로 연비'를 상자 그림으로 표현
mpg = pd.read_csv('./input/mpg.csv')
print(mpg.head())
# manufacturer model displ year cyl trans drv cty hwy fl category
# 0 audi a4 1.8 1999 4 auto(l5) f 18 29 p compact
# 1 audi a4 1.8 1999 4 manual(m5) f 21 29 p compact
# 2 audi a4 2.0 2008 4 manual(m6) f 20 31 p compact
# 3 audi a4 2.0 2008 4 auto(av) f 21 30 p compact
# 4 audi a4 2.8 1999 6 auto(l5) f 16 26 p compact
# mpg.csv : '구동 방식별 고속도로 연비 평균'
# displ(배기량)
# hwy(고속도로 연비)
# drv(구동방식)
sns.boxplot(data=mpg, x='drv', y='hwy')
plt.show()
# 상자 그림은 값을 크기순으로 나열해 4등분했을 때 위치하는 값인 '사분위수'를 이용해 만듬.
# 다음은 상자 그림의 요소가 나타내는 값
# 상자 그림 값 설명
# 상자 아래 세로선 아랫수염 하위 0 ~ 25% 내에 해당하는 값
# 상자 밑면 1사분위수(Q1) 하위 25% 위치 값
# 상자 내 굵은 선 2사분위수(Q2) 하위 50% 위치 값 (중앙값)
# 상자 윗면 3사분위수(Q3) 하위 75% 위치 값
# 상자 위 세로선 윗수염 하위 75 ~ 100% 내에 해당하는 값
# 상자 밖 가로선 극단치 경계 Q1, Q3 밖 1.5 IQR 내 최대값
# 상자 밖 점 표식 극단치 Q1, Q3 밖 1.5 IQR을 벗어난 값
# * IQR(사분위 범위)은 1사분위수와 3사분위수의 거리(직사각형의 높이)를 뜻하고,
# '1.5 IQR'은 IQR의 1.5배을 뜻함.
# 출력된 그래프를 보면 각 구동방식의 고속도로 연비 분포를 알수 있음.
# * 전륜구동(f)은 26 ~ 29 사이의 좁은 범위에 자동차가 모여 있는 뾰족한 형태의 분포.
# 수염의 위아래에 점 표식이 있는 것을 보면 연비가 극단적으로 높거나 낮은 자동차들이 있음.
# * 4륜구동(4)은 17 ~ 22 사이에 자동차 대부분이 모여 있음.
# 중앙값이 상자 밑면에 가까운 것을 보면 낮은 값 쪽으로 치우친 형태의 분포
# * 후륜구동(r)은 17 ~ 24 사이의 넓은 범위에 자동차가 분포.
# 수염이 짧고 극단치가 없는 것을 보면 자동차 대부분이 사분위 범위에 해당한다는 것을 알수 있음.
9. 산점도 scatter plot - 변수 간 관계 표현하기
- 산점도 : 데이터를 x축과 y축에 점으로 표현한 그래프
- 나이와 소득처럼 연속값으로 된 두 변수의 관계를 표현할 때 사용
- 1) 산점도 만들기
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
mpg = pd.read_csv('./input/mpg.csv')
print(mpg.head())
# manufacturer model displ year cyl trans drv cty hwy fl category
# 0 audi a4 1.8 1999 4 auto(l5) f 18 29 p compact
# 1 audi a4 1.8 1999 4 manual(m5) f 21 29 p compact
# 2 audi a4 2.0 2008 4 manual(m6) f 20 31 p compact
# 3 audi a4 2.0 2008 4 auto(av) f 21 30 p compact
# 4 audi a4 2.8 1999 6 auto(l5) f 16 26 p compact
print(mpg.tail())
# manufacturer model displ year cyl ... drv cty hwy fl category
# 229 volkswagen passat 2.0 2008 4 ... f 19 28 p midsize
# 230 volkswagen passat 2.0 2008 4 ... f 21 29 p midsize
# 231 volkswagen passat 2.8 1999 6 ... f 16 26 p midsize
# 232 volkswagen passat 2.8 1999 6 ... f 18 26 p midsize
# 233 volkswagen passat 3.6 2008 6 ... f 17 26 p midsize
# mpg.csv : '구동 방식별 고속도로 연비 평균'
# displ(배기량)
# hwy(고속도로 연비)
# drv(구동방식)
# sns.scatterplot() : 산점도 만들 때 사용
# data : 그래프를 그리는 데 사용할 데이터 프레임을 입력
# x, y : x축과 y축에 사용할 변수(데이터 프레임의 열)를 ''을 이용해 문자 형태로 입력
# x축은 displ, y축은 hwy를 나타낸 산점도 만들기
# mpg 데이터의 displ(배기량) 변수를 x축에, hwy(고속도로 연비) 변수를 y축에 놓음
sns.scatterplot(data=mpg, x='displ', y='hwy')
plt.show()

# 1) 축 범위 설정하기
# 축은 기본적으로 최소값에서 최대값까지 모든 범위의 데이터를 표현하도록 설정
# 데이터 전체가 아니라 일부만 표현하고 싶을 때는 축 범위를 설정
# sns.set() : 범위를 설정하는데 사용
# xlim, ylim을 이용해 설정
# xlim을 이용해 x축 범위 3 ~ 6으로 제한
sns.scatterplot(data=mpg, x='displ', y='hwy').set(xlim=(3,6))
plt.show()

# 2) 종류별로 표시 색깔 바꾸기
# hue를 이용하면 표식 marker의 색깔을 종류별로 다르게 표현할 수 있음
# drv별로 표식 색깔 다르게 표현
sns.scatterplot(data=mpg, x='displ', y='hwy', hue='drv')
plt.show()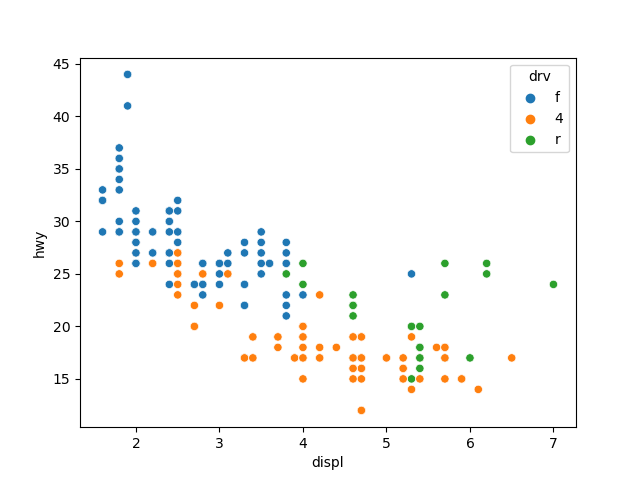
# 3) 그래프 활용하기
# 그래프 설정 바꾸기
plt.rcParams.update({'figure.dpi': '150'}) # 해상도, 기본값 72
plt.rcParams.update({'figure.figsize': [8,6]}) # 그림 크기, 기본값 [6,4]
plt.rcParams.update({'font.size': '15'}) # 글자 크기, 기본값 10
plt.rcParams.update({'font.family': 'Malgun Gothic'}) # 폰트, 기본값 sans-serif
# 여러 요소를 한 번에 설정하려면 {}에 설정값을 나열
plt.rcParams.update({'figure.dpi': '150',
'figure.figsize': [0, 6],
'font.size':'15',
'font.family':'Malgun Gothic'})
sns.scatterplot(data=mpg, x='displ', y='hwy')
plt.show()
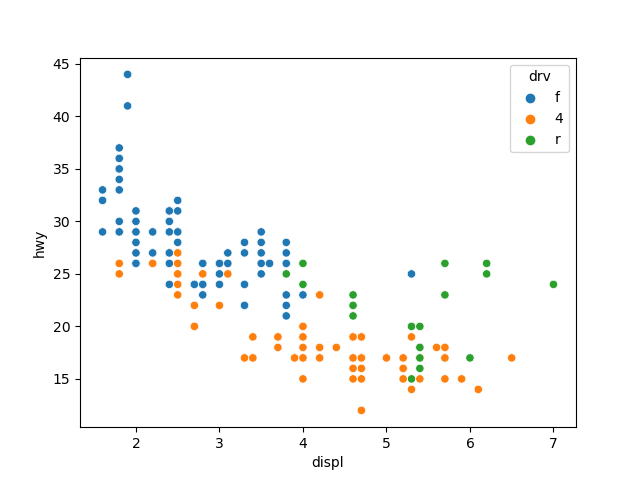
10. 평균 막대 그래프 만들기
- 평균 막대 그래프는 평균값의 크기를 막대 길이로 표현한 그래프
- 여러 집단의 평균 값을 비교할 때 평균 막대 그래프를 주로 사용
# mpg 데이터에서 drv(구동방식)별 hwy(고속도록 연비) 평균을 나타낸 막대 그래프를 만듬
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
mpg = pd.read_csv('./input/mpg.csv')
# print(mpg.head())
# 1) 집단별 평균표 만들기
# 평균 막대 그래프를 만들려면 집단별 평균값을 담은 데이터 프레임이 필요
# '구동 박식별 고속도로 연비 평균'을 담은 데이터 프레임을 만듬
# drv별로 분리하고 hwy 평균 구하기
# agg(mean_hwy=('hwy', 'mean') -> mean_hwy열을 생성하면서 'hwy'열의 평균(mean)값을 입력
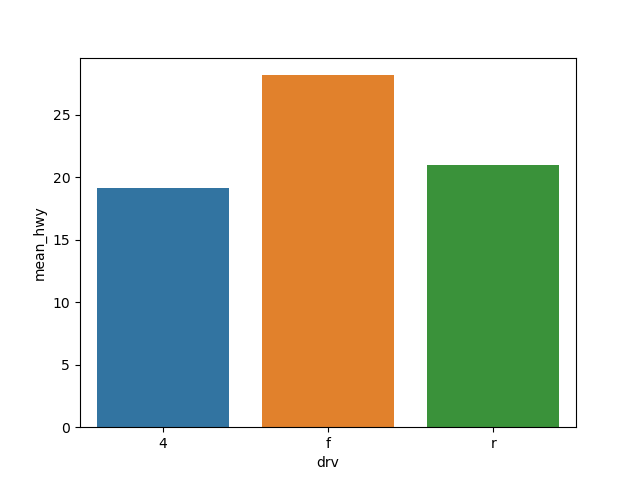
df_mpg = mpg.groupby('drv').agg(mean_hwy=('hwy', 'mean'))
print(df_mpg)
# mean_hwy
# drv
# 4 19.174757
# f 28.160377
# r 21.000000
# 출력 결과를 보관 집단을 나타낸 변수 drv가 인덱스로 바뀌어 mean_hwy 아래에 표시
# seaborn으로 그래프를 만들려면 값이 변수에 담겨 있어야 함
# -> 인덱스가 아니라 열로 만들어져야 함
# 변수를 인덱스로 바꾸지 않고 원래대로 유지하려면 df.groupby()에 as_index = False를 입력
df_mpg = mpg.groupby('drv', as_index=False).agg(mean_hwy=('hwy', 'mean'))
print(df_mpg)
# drv mean_hwy
# 0 4 19.174757
# 1 f 28.160377
# 2 r 21.000000
# 2) 그래프 만들기
# 생성된 데이터 프레임을 이용해 막대 그래프를 만듬
# sns.barplot() : 막대 그래프 만들 때 사용
# data : 데이터 프레임을 지정
# x : x축에 범주를 나타낸 변수
# y : y축에 평균값을 나타낸 변수
sns.barplot(data=df_mpg, x='drv', y='mean_hwy')
plt.show()
# 3) 크기순으로 정렬하기
# 막대 정렬 순서는 그래프를 만드는데 사용한 데이터 프레임의 행 순서에 따라 정해짐
# 앞에서 출력한 그래프를 보면 drv 막대가 4, f, r 순으로 정렬
# 크기 순으로 정렬하려면 그래프를 만들기 전에 df.sort_values()를 이용해 데이터 프레임을 내림차순으로 정렬
# 데이터 프레임 정렬하기
df_mpg = df_mpg.sort_values('mean_hwy', ascending=False)
# 막대 그래프 만들기
sns.barplot(data=df_mpg, x='drv', y='mean_hwy')
plt.show()
- 2) 빈도 막대 그래프
- 빈도 막대 그래프는 값의 빈도(개수)를 막대 길이로 표현한 그래프
- 여러 집단의 빈도를 비교할 때 빈도 막대 그래프를 자주 사용
# 02 빈도 막대 그래프
# 1) 집단별 빈도표 만들기
# 빈도 막대 그래프를 만들려면 집단별 빈도를 담은 데이터 프레임이 필요
# df.agg()에 빈도를 구하는 함수 count를 적용해 '구동 방식 별 빈도'를 담은 데이터 프레임을 만듬
# 집단별 빈도표 만들기
df_mpg = mpg.groupby('drv', as_index=False).agg(n=('drv', 'count'))
print(df_mpg)
# drv n
# 0 4 103
# 1 f 106
# 2 r 25
# 2) 그래프 만들기
# sns.barplot()을 적용해 막대 그래프 만듬
# 막대 그래프 만들기
sns.barplot(data=df_mpg, x='drv', y='n')
plt.show()

# sns.barplot() 사용할 때 df.groupby()와 df.agg()를 이용해 집단별 빈도표를 만드는 작업했음
# 대신 sns.countplot()을 이용하면 원데이터를 바로 이용해 빈도 막대 그래프를 만들 수 있음
# 빈도 막대 그래프 만들기
sns.countplot(data=mpg, x='drv')
plt.show()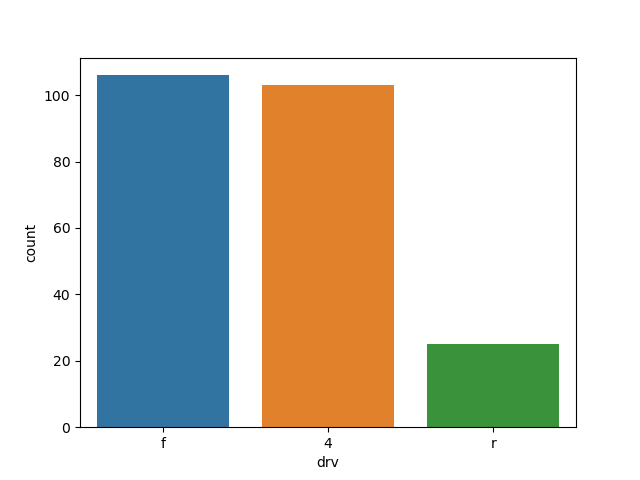
# 두 그래프는 x축의 순서가 다름
# sns.barplot()으로 만든 그래프는 x축 순서가 4, f, r인 반면
# sbs.countplot()로 만든 그래프는 f, 4, r
# 이는 sns.barplot()에 사용한 df_mpg와 sns.countplot()에 사용한 mpg의 drv 값 순서가 다르기 때문
# 데이터 프레임에서 변수의 값 순서는 데이터 프레임에 입력된 행의 순서에 따름
# mpg의 drv는 0~6행이 f, 7~17행이 4, 18~27이 r로 되어 있으므로 값의 순서는 f, 4, r
# 변수의 고유값을 출력하는 unique()를 이용하면 값의 순서를 알 수 있음
print(mpg['drv'].unique()) # ['f', '4','r']
# df_mpg의 drv는 값의 순서가 알파벳 순으로 되어 있음
# groupby()를 이용해 데이터 프레임을 요약하면 값의 순서가 알파벳순으로 바뀌기 때문
print(df_mpg['drv'].unique()) # ['4' 'f' 'r']
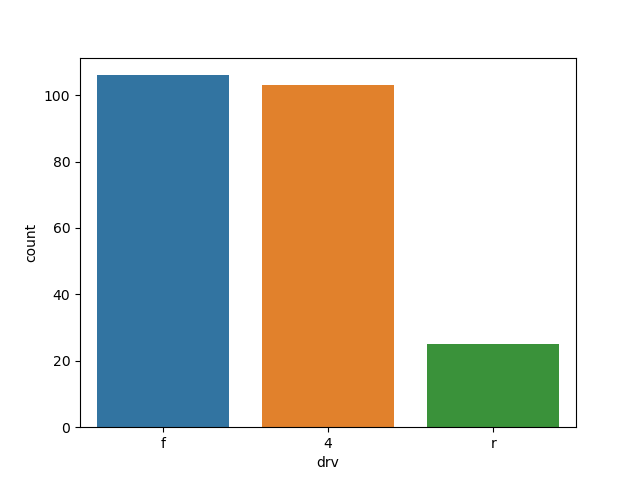
# 3) 막대 정렬하기
# sns.countplot()으로 만든 그래프의 막대를 정렬하려면 order에 원하는 순서로 값을 입력하면 됨
# 4, f, r 순으로 막대 정렬
sns.countplot(data=mpg, x='drv', order=['4', 'f', 'r'])
plt.show()
# sns.countplot()의 order에 mpg['drv'].value_counts().index를 입력하면
# drv의 빈도가 높은 수능로 막대를 정렬
# mpg['drv'].value_counts().index는 빈도가 높은 순으로 변수의 값을 출력
# drv의 값을 빈도가 높은 순으로 출력
mpg['drv'].value_counts().index
# drv 빈도 높은 순으로 막대 정렬
sns.countplot(data=mpg, x='drv', order=mpg['drv'].value_counts().index)
plt.show()
11. 연습문제
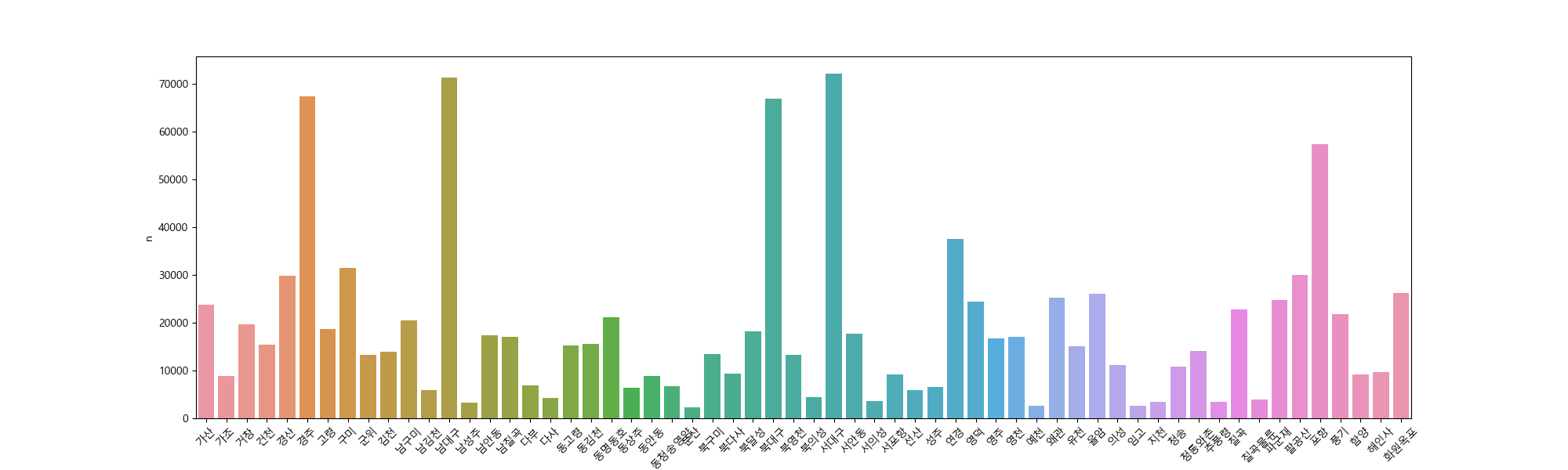
# 공공 데이터 포탈에서 다운받은 '한국도로공사_대구경북권 톨게이트 진출입 일교통량'을 검색.
# 상세 정보에서 한국도로 공사링크를 제공.
# 링크를 따라간 후 집계주기 1일, 분기 : 2023년 4분기 파일을 다운로드
#
#
# 1. 집계일자, 영업소명, 입출구명, TCS하이패스명, 총교통량을 제외한 나머지 컬럼 삭제
#
# 2. 2023년 10월 1일의 각 영업소별 총 교통량을 막대 그래프로 출력
df = pd.read_csv('./input/TCS_B3_04_03_238959.csv', encoding='ANSI')
print(df.head())
# 한글이라서 코드 입력
matplotlib.rcParams['font.family'] = 'Malgun Gothic'
df1 = df[['집계일자','영업소명', '입출구명','TCS하이패스명','총교통량']]
# print(df1.head())
# print(df1.tail())
print(df1.info())
want_month = df1['집계일자'] == '2023-10-01'
df2 = df1[want_month]
print(df2.tail())
df3 = df2.groupby('영업소명', as_index=False).agg(n=('총교통량', 'sum'))
print(df3.tail())
plt.figure(figsize=(20,6))
plt.xticks(rotation=45)
sns.barplot(data=df3, x='영업소명', y='n')
plt.show()
공부 과정을 정리한 것이라 내용이 부족할 수 있습니다.
부족한 내용은 추가 자료들로 보충해주시면 좋을 것 같습니다.
읽어주셔서 감사합니다 :)